
As data science techniques continue to evolve, we have the unique opportunity to effect impactful change in the healthcare industry, allowing for more effective, prompt, and personalized patient care. This weblog explains just a few of the many ways data science is currently being implemented in healthcare to inform aspiring data scientists about potential career paths. I also hope to demonstrate the potential of data science to impact the public good.
Personalized Medicine
Data science algorithms targeted at personalized medicine aim to tailor the care patients receive to their specific health history and circumstances. The goal is to improve clinical outcomes for patients.
Applications to Oncology
Healthcare is one of many areas facing the increasing challenge of wrangling the large amount of data. As data collection methods and frequency improve, we are able to collect patient clinical data (e.g., doctors’ visits, laboratory data, radiology data, emergency department visits, etc.), demographic data, genetic data, socioeconomic data, self-reported quality of life metrics, and more, both for current patients as well as historical patients who have signed appropriate data/research consents. This allows us to use data collected from past patients, including their treatment plans and outcomes, to inform the treatment plans of future patients.
In oncology, specifically, recent advances have allowed researchers to “generate genomic and molecular profiles of tumors,” resulting in massive data, and deep machine learning for sophisticated prediction methods.” By identifying key genetic or molecular markers in tumors, then analyzing data to identify how patients with those markers respond to certain cancer treatment plans, more targeted and effective treatment plans can be crafted for future patients with similar tumor genetics profiles. One consortium working towards this goal is Project GENIE, launched in 2015, which brings together tumor genetic profiles from over 50,000 patients across 19 institutions. The goal is to tie this data with clinical data regarding patient treatments and outcomes to “design biomarker-driven clinical trials” in order to “find genomic determinants of response to therapy.”
One example is a study conducted by the University College Dublin, which attempted to predict if patients with ER-positive, HER2-negative breast cancer would have a “pathological complete response (pCR) to neoadjuvant chemotherapy.” The researchers chose this specific subtype of breast cancer patients because pCR is often quite low in that subtype, meaning that patients could waste essential treatment time pursuing an ineffective therapy. The researchers investigated four different multi-gene prognostic signatures’ abilities to predict a patient’s pCR. Data used across the four signatures included patient data regarding prognostic genes, reference genes, master transcriptional regulator genes, “genes representing 15 immune cell sub-populations,” tumor size, and nodal status. When these four prognostic signatures are used in a logistic regression algorithm, the researchers found that they were “significantly predictive of pCR to neoadjuvant chemotherapy,” meaning they were quite predictive in determining which patients would have a complete response to neoadjuvant chemotherapy versus which ones would not. Such algorithms can serve as key decision-support tools aiding oncologists in identifying optimal treatment plans for their patients based on their specific tumor genetic profiles.
Data science also has the ability to help with other aspects of oncology treatment. An application is using ML algorithms to identify cancer via pathology. For example, a computational pathologist at Memorial Sloan Kettering Cancer Center in New York City used a very large dataset of 12,160 slides of prostate needle biopsies, with a hold-out test dataset of 1,824 slides, to train a deep learning model using the Multiple Instance Learning framework. The goal of the model was to classify the prostate cancers it was presented with, a task that can be quite difficult because “classification is frequently based on the presence of very small lesions that can comprise just a fraction of 1% of the tissue surface.” In order to capture all the complexity of the biopsies of the tissue surface, both feature embeddings and Principal Component Analysis (PCA) were used to summarize the feature space. In the image below, the four sub-images pulled out “are sampled from different regions of the 2D PCA embedding.” Readers can see which area of the plot they correspond to and if they are within the positive (teal) or negative (orange) class, as well as visualize model performance by looking at how many predictions were correct (points represented by circles) versus incorrect (points represented by triangles).
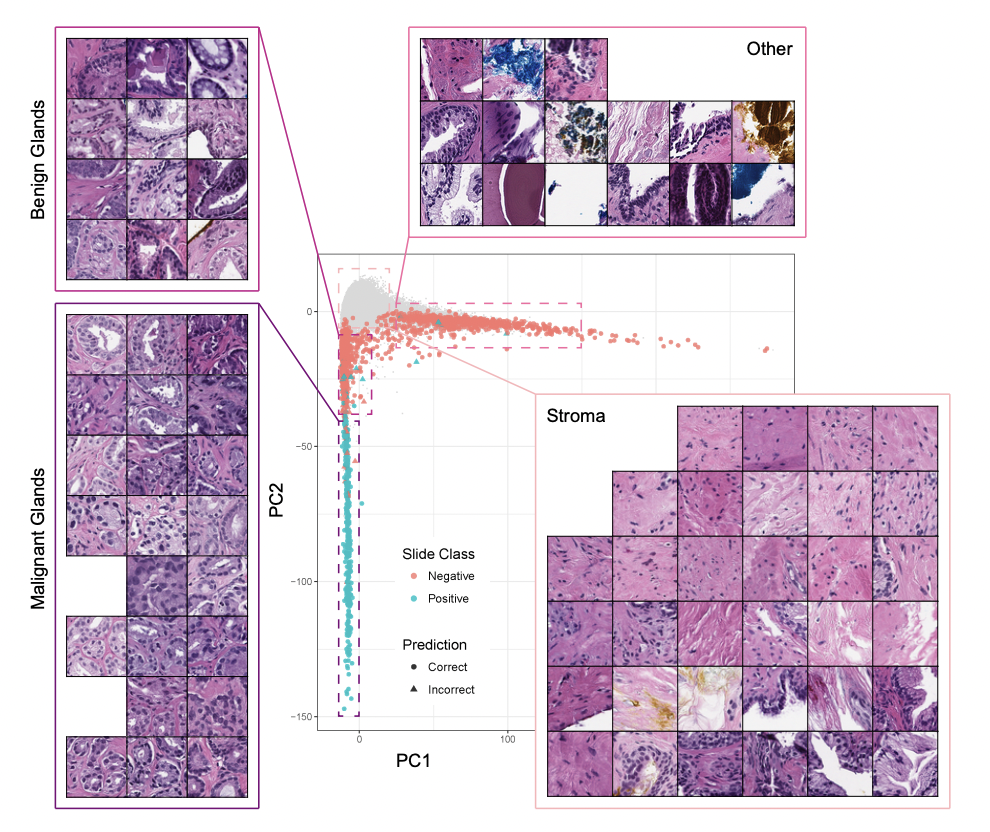
Despite the intense complexity present of this problem, the resulting model had an impressive Area Under the receiver operating characteristic Curve (AUC) “of 0.98 and a false negative rate of 4.8%,” which the authors hope will open the door to more ML techniques being used as diagnostic aids and clinical decision support systems.
Predicting Patient Deterioration
As in the case of cancer patients, other areas of medicine also have both the blessing and curse of access to a myriad of forms of patient data, both present and historical. In the case of patients being monitored, this allows for AI algorithms to identify patterns in patient data that, based on past patient data, may indicate imminent patient deterioration. These algorithms commonly consider valuable clinical data, such as heart rate, respiratory rate, blood pressure, oxygen saturation, body temperature, level of consciousness (via the Glasgow Coma Score or AVPU scale), and mean arterial pressure. Data collection frequency for the aforementioned ranges “from once every 5 seconds in hospital wards to 3-7 times per week in an ambulatory setting.” Patient vital data is often combined with other patient demographic data (e.g., “age, gender, weight, ethnicity”), comorbidities, and chief complaint data to create personalized predictions. Adverse patient outcomes/events that these algorithms can predict include cardiorespiratory decompensation, cardiac arrest, onset of sepsis, septic shock, ICU admissions, and death. Data science methods, including predictive modeling, can provide clinicians early warning to either prevent or prepare to respond to serious, adverse patient events such as the aforementioned.
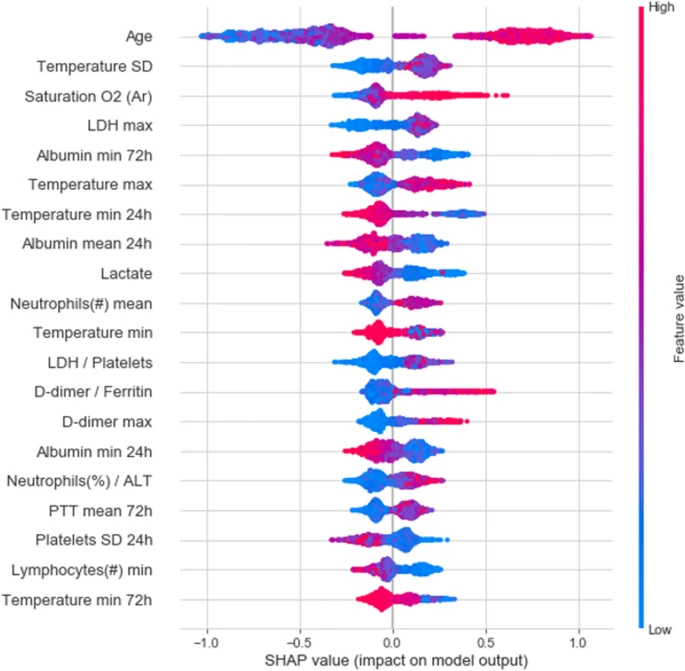
In recent years, as COVID-19 pushed the healthcare system to its breaking point, early warning algorithms became increasingly helpful. Researchers in Israel created an algorithm to predict the deterioration of COVID-19 patients using longitudinal electronic healthcare records of 662 patients in “Sheba Medical Center (Sheba), the largest hospital in Israel,” then validating the model performance on data from 417 patients from “the second largest hospital in Israel, the Tel-Aviv Sourasky Medical Center (TASMC).” The data used in the model included “demographics, background disease, vital signs and lab measurements.” As COVID-19 became widespread, clinicians adapted the National Early Warning Score 2 (NEWS2) for clinical deterioration of patients to COVID-19 patients, coining the modified metric the mNEWS2. This algorithm aimed to predict patient deterioration by predicting when a patient would develop a “high mNEWS2 score (≥ 7)” within the next 7 to 30 hours. The resulting model had an AUC of 0.76 and an area under the precision-recall curve (AUPR) of 0.7. The authors state this may be in part due to the “lower temporal resolution” and “higher rate of missing values” in the TASMC hospital data when compared to the Sheba hospital data. To better understand key predictive features in this model, the “20 features with highest mean absolute SHAP values” are depicted below, with “absolute value indicates the extent of the contribution of the feature” and “color representing the value of the feature from low (blue) to high (red).”
Another example of an early warning algorithm was developed by the University of Oxford’s Institute of Biomedical Engineering and the Nuffield Department of Clinical Neurosciences. The algorithm used “vital signs, laboratory tests, comorbidities, and frailty” data from 230,415 patients admitted to one hospital to develop a “Hospital-wide Alerting via Electronic Noticeboard (HAVEN) system to identify hospitalized patients at risk of reversible deterioration.” When tested on patient data from 266,295 patients admitted to four different hospitals, HAVEN had a c-statistic of 0.901 with a 95% confidence interval of 0.898–0.903. “With a precision of 10%, HAVEN was able to identify 42% of cardiac arrests or unplanned ICU admissions with a lead time of up to 48 hours in advance,” allowing clinicians to intervene much earlier for the identified patients.
A similar example from within the United States is the Mayo Clinical Early Warning Score (MC-EWS), an algorithm that seeks to “predict general care inpatient deterioration (resuscitation call, intensive care unit transfer, or rapid response team call)” within the next 24 hours for patients admitted to a hospital. The “training and internal validation datasets were built using 2-year data” from a highly specialized hospital in the Midwest. The training dataset included data from 24,500 patients, the internal validation from 25,784 patients, and the external validation from 53,956 patients. The resulting algorithm had a C-statistic of 0.913 for the internal validation dataset and 0.937 for the external validation dataset, demonstrating “excellent discrimination.” Furthermore, the researchers seek to highlight how important it is that such algorithms generate as few alerts (and false positives) as possible so the alerts that are generated are essential and unnecessary alerts do not distract clinicians from other patients. To that end, they highlight that the MC-EWS score generated only 0.7 alerts per day per 10 patients, a reasonable amount for clinicians to respond to.
Logistics
Data science algorithms targeted at healthcare logistics aim to cut down the administrative burdens of healthcare to get patients the care they need faster.
Prior Authorizations
Prior authorizations are requests doctors (or staff in their offices) fill out to ask an insurance company if they will cover certain medical procedures for a specific patient. For certain procedures, such as those that may span a long period of time (e.g., months of physical therapy) or are complex and costly procedures (e.g., surgeries), insurance companies require clinicians to fill out these prior authorizations and get approval before administering the procedure.
In the status quo healthcare system, prior authorizations are submitted to insurance companies who have nurses manually review a patient’s medical history as well as documentation the clinician submitted with the authorization request to render a decision on the authorization. Due to this time-intensive manual review process, patients may wait days to weeks for approval before being able to schedule the procedures they need. According to the 2016 AMA Prior Authorization Physician Survey, 90% of physicians surveyed reported care delays associated with the prior authorization process. 44% of physicians reported that those care delays were “often or always.”
Data science has the ability to drastically change this process, decreasing waiting periods leading to care delays. One example of a tech start-up focused on this problem is Cohere Health (to be transparent: I currently work as a data scientist at Cohere Health). Cohere Health uses rules-based algorithms, which often include features extracted or generated using machine learning models, to automatically approve prior authorizations whenever possible. When an algorithm classifies an authorization as “should be approved,” it is automatically approved (within minutes of submission), allowing patients to immediately schedule procedures they need.
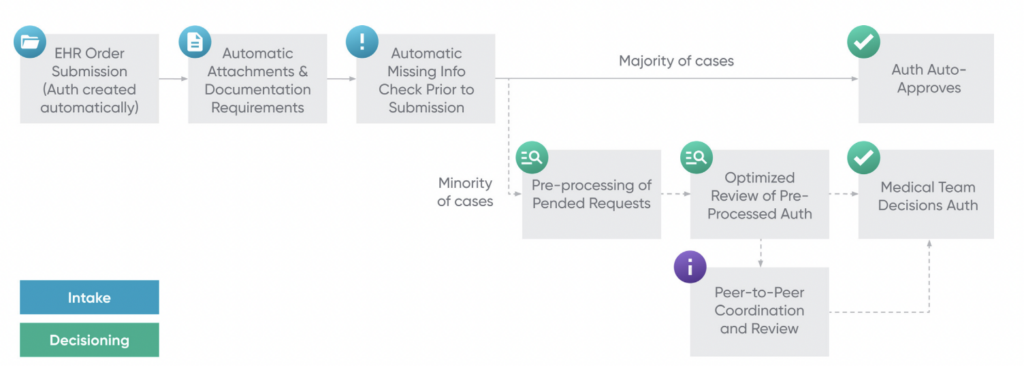
When an algorithm classifies an authorization as “should be denied,” it is sent to a nurse for the manual review process to ensure algorithms are never denying care, only facilitating quicker approvals. The machine learning models that provide information to the rules-based algorithms utilize a variety of data mining techniques that consider structured data (e.g., patient claims, age, documented diagnoses, etc.), unstructured data (e.g., clinical notes doctors submit with authorizations, MRI/CT scan reports, etc.), and publicly-available data. Thanks to these algorithms, many patients are able to get immediate approvals, and those who do not are still often able to get much faster responses since the nurses now have much lower volumes of authorizations to manually review. Below is a flowchart of Cohere’s workflow, which uses data mining tools (including NLP, parametric models, and more) to check for missing information prior to submission, auto approve authorizations when possible, and pre-process authorization requests pended to nurse or physician review by parsing out key data necessary for approvals when auto-approvals are not possible. Cohere reports that its outcome measures include 70% faster access to care due to the aforementioned.
In addition to algorithmic auto-approvals, Cohere’s platform has the ability to nudge clinicians to submit authorization requests that are likely to get approved while they are filling out the request. For example, if a clinician wants to request 8 sessions of physical therapy, but Cohere’s rules-based algorithms know that the patient’s insurance only covers 5 sessions per prior authorization, clinicians will be shown a nudge suggesting they only request 5 sessions. These preemptive nudges allow clinicians to submit the most appropriate prior authorization for their patients, decreasing denials by 63% and allowing patients to get the care they need more promptly rather than requiring repeated authorization submissions until the insurance company approves one. Cohere reports that these preemptive nudges allow them to approve 80-90% of prior authorizations they receive immediately upon submission.
[RELATED RESOURCE] Ready to advance your healthcare career with data science? Get our guide to selecting the right master’s program.
Staffing Models
One of the greatest modern healthcare challenges is how to staff hospitals appropriately in order to minimize patient care delays. As nationwide physician and nurse shortages increase, these challenges come to the forefront of healthcare even more, especially in Emergency Departments (EDs). According to the Journal of the American Medical Association, ” from 1990 to 2009, the number of hospital EDs in nonrural areas declined by 27%.” Furthermore, the Annals of Emergency Medicine reports that “the field will see a surfeit of 9,400 emergency physicians by 2030,” a looming physician shortage exacerbated by the fact that 555 emergency medicine residency positions went unfilled in the 2023 match cycle due to decreasing applicants. However, “patient demand for emergency department (ED) services in the United States has increased by 50 percent since 1994.”
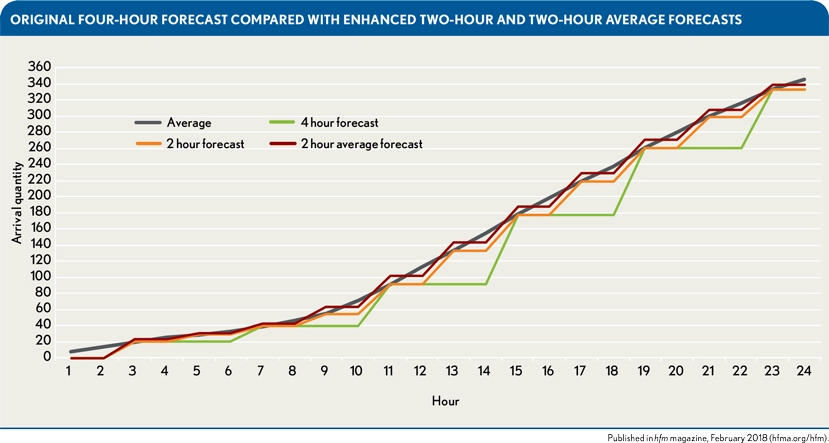
As EDs experience worsening physician and nurse shortages, dynamic staffing that takes demand into account will become increasingly essential. One example was a collaboration between Grand Valley State University and Spectrum Health Butterworth Hospital. By using retrospective patient volume data from Butterworth Hospital’s ED, researchers at the university were able to model future patient volume based on seasonal patterns identified using time series analyses and modeling. Patient volume was forecasted in 2-hour increments to allow for maximal fine-tuning of staff needed. The graph below shows the algorithm’s ability to predict patient arrival on Mondays from July through August at Butterworth Hospital’s ED quite well, especially when the researchers opted for a 2-hour forecast rather than a 4-hour forecast.
The predicted patient volume was then used to “create a staffing model that meets the demand of fluctuating arrival quantities within budgetary constraints.” Due to that model, within 30 days of 2017, “the average overtime hours decreased from 281 in fiscal year 2016 to 127.” Ten months after the implementation of these models, cost savings totaled $110,113.
In addition to cost savings, the ability to staff based on patient volume also allows for increased staff to be present during patient surges and less staff to be asked to work during lower-volume hours, decreasing patient care delays and overtime required of staff. Dr. Parker, a Senior Vice President at SCP Health, also states that forecasting patient volume via ML algorithms allows for clinicians to get their schedules much earlier as well, allowing for increased work-life balance and avoiding the need to increase staff last minute due to unanticipated patient volume. These quantitative and qualitative benefits of using data science for dynamic staffing in EDs, as well as other hospital specialties, may prove to be essential in combating increased patient volumes and clinician shortages.
Conclusion
The algorithms and use cases discussed above are just some of the many, growing applications of data science to healthcare. A few other use cases include: (a) identifying populations at high-risk for certain chronic diseases and increasing preventive care measures for them, (b) flagging medication errors in a patients’ electronic health records, (c) identifying care access barriers (e.g. lack of internet or transportation access) and adapting patient care to them, and (d) predicting maintenance for equipment (e.g. an MRI scanner) prior to actual equipment breakdowns or malfunctions. Once again, the use cases enumerated in this weblog just scratch the surface of data science applications to healthcare that currently exist, let alone those that could develop within the next few years as research and partnerships within the health tech industry skyrocket.
As somebody who has worked in health tech for a few years now, I have often seen a reluctance to adopt tech solutions or a lack of awareness as to how precisely they could help patients. My goal in writing this is to demonstrate a few tangible ways data science can help healthcare, both clinically and operationally (in tandem with robust data governance and data privacy practices, of course). Hopefully, as healthcare leaders look to solve more challenges in the space, they bring tech talent into those working groups as well. My hope is also that data scientists and machine learning engineers that seek to have a fulfilling, impactful career consider health tech as well. The industry provides ample opportunities to truly impact patient care by working hand-in-hand with clinicians to develop algorithms to make healthcare delivery both more efficient and personalized.


