

Not All Models Are Built to Tell You the Truth
In the landscape of data analysis, models come in many forms, but at a foundational level, they can be divided into those that strive to explain and those that aim to predict. Statistical models fall into the first category. They attempt to describe the underlying data-generating process, quantify uncertainty, and produce interpretable results. Machine learning models, by contrast, are less focused on interpretation and more concerned with identifying patterns that hold up when applied to new, unseen data. These methodologies are often grouped together in conversations about data science, yet they operate under fundamentally different assumptions, rely on different mathematical strategies, and are built to serve distinct purposes.
Understanding the distinction between statistical modeling and machine learning is essential not just for technical precision, but also for ethical judgment, practical implementation, and scientific soundness. This piece explores their respective philosophical foundations, mathematical design choices, and practical aims, drawing on concrete examples and formal mathematical logic to highlight what sets each apart.
Assumptions and Objectives: Inference vs. Prediction
At the core of a statistical model lies the assumption of a structured, usually parametric, data-generating process. A familiar example is the classical linear regression model, which can be written as
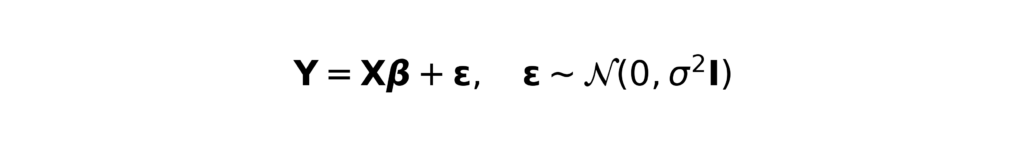
In this formulation, Y is the outcome vector, X is the design matrix of predictor variables, β is the vector of unknown coefficients, and ε is a vector of normally distributed errors with constant variance. The primary goal is to estimate the coefficients β, quantify their uncertainty, and test hypotheses such as H0: βj = 0 using standard tools like confidence intervals and p-values. This framework lends itself naturally to inference, drawing conclusions about population parameters based on observed data. Machine learning models, in contrast, are typically agnostic to the underlying structure of the data. Instead of estimating interpretable parameters, they seek to learn a function ⨍: X → Y that minimizes the expected loss on future observations. Formally, the goal is to minimize the population risk
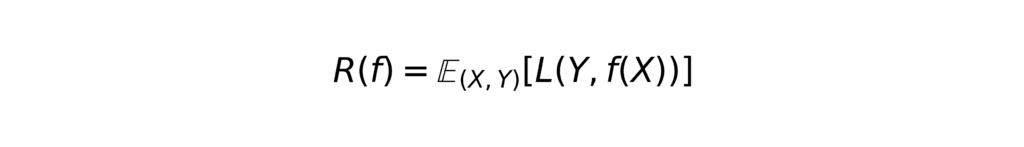
where L is a loss function such as squared error or cross-entropy, depending on whether the problem is one of regression or classification. Because the true distribution of (X,Y) is unknown, we minimize the empirical risk over a sample of n observations:
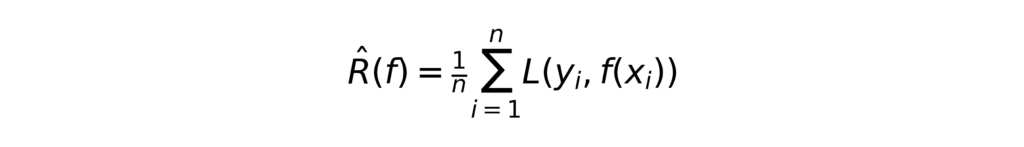
This empirical risk minimization framework underpins most supervised learning algorithms, from decision trees to neural networks.
Structure vs. Flexibility: The Role of Inductive Bias
Statistical models generally require strong assumptions to ensure the validity of inference. For example, linear regression assumes linearity between predictors and outcome, normality of residuals, homoscedasticity, and independence of observations. These assumptions enable the derivation of the sampling distribution of β, which in turn allows for rigorous uncertainty quantification:
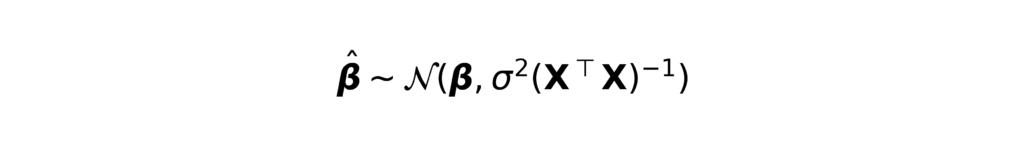
Violating these assumptions can lead to biased or inefficient estimators, invalid p-values, or misleading conclusions. Machine learning models tend to operate with weaker or more flexible assumptions. Many nonparametric methods such as k-nearest neighbors, decision trees, and kernel methods do not assume linearity or a specific functional form. Their flexibility comes at a cost: increased variance and reduced interpretability. Complex models like deep neural networks are highly expressive but often require large amounts of data and careful regularization to avoid overfitting.
This trade-off is often summarized through the lens of the bias–variance decomposition. For a squared loss function, the expected prediction error for a point x can be decomposed as
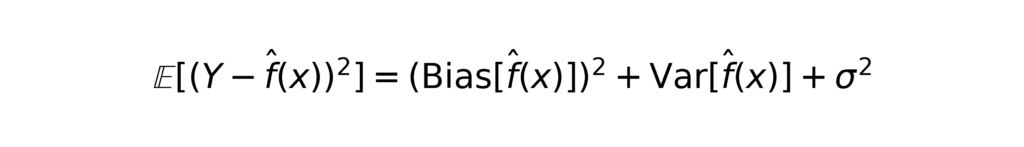
where σ2 represents irreducible error. Statistical models often exhibit low variance but may suffer from high bias if their assumptions are incorrect. Machine learning models, conversely, can achieve low bias due to their flexibility, but they must be carefully regularized to control variance.
Before we explore the specific objectives behind statistical models and machine learning, it’s useful to take a step back and look at how these two approaches relate to each other. Both are used to analyze data and support decision-making, but they come from different traditions and are often applied with different goals in mind. The diagram below highlights where they intersect and where their priorities begin to diverge.

Figure 1. Conceptual overlap between statistical models and machine learning.
While both approaches are used in supervised learning contexts such as regression and classification, statistical models focus on inference and parameter estimation, whereas machine learning models emphasize predictive accuracy and adaptability.
In machine learning, the central concern is how well the model generalizes. Techniques such as cross-validation, early stopping, and hyperparameter tuning are used to optimize predictive performance on unseen data. A model that performs well in-sample but poorly out-of-sample is penalized through measures like the validation loss or test set error. The success of a machine learning model is often judged by metrics such as accuracy, precision, recall, F1 score, or area under the ROC curve, depending on the context. More importantly, optimizing for inference does not guarantee good prediction, and vice versa. A model with highly significant coefficients may generalize poorly, while a black-box model with superb accuracy may offer no insight into why the predictions are what they are.
What Are You Optimizing?
The mathematical objectives further illustrate the philosophical divide. In classical statistics, the focus is on parameter estimation and hypothesis testing. The statistician cares whether the effect of a predictor is real, statistically significant, and robust to variation in the data. The quantities of interest: coefficients, variances, confidence intervals have direct scientific interpretation.
Visual Comparison: When Linearity Fails
To illustrate how these modeling philosophies diverge in practice, consider a dataset generated from a nonlinear function. The statistical model (left) fits a straight line, unable to capture the true relationship. The machine learning model (right), using a Random Forest, adapts to the shape of the data without assuming a functional form.

Figure 2. Modeling a nonlinear relationship
The OLS model on the left assumes a linear relationship and fails to capture the curvature in the data. The Random Forest model on the right, trained on the same inputs, successfully models the nonlinearity without requiring explicit assumptions.
Example: Comparing Inference and Prediction with Linear Models
Let’s take a simple dataset where we aim to understand and predict a continuous outcome based on a single predictor. Before jumping into the code, it’s helpful to clarify what this example is meant to show. We’ll use a simple synthetic dataset to compare two modeling strategies: one based on statistical inference and one focused on prediction. The statistical model will estimate relationships and evaluate their significance using standard tests, while the machine learning model will aim to make accurate predictions on new data. If you’re not deeply familiar with either approach, that’s fine—the purpose is to highlight the difference in goals, not to get lost in the code.
import numpy as np import pandas as pd import statsmodels.api as sm from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split # Generate synthetic data np.random.seed(42) X = np.random.normal(5, 2, 100) noise = np.random.normal(0, 1, 100) Y = 3 * X + 7 + noise # True model df = pd.DataFrame({'X': X, 'Y': Y})
Approach 1: Statistical Model with statsmodels (Inference)
# Add intercept term X_sm = sm.add_constant(df['X']) # Fit the model model_sm = sm.OLS(df['Y'], X_sm).fit() # Summary includes coefficients, # confidence intervals, and p-values print(model_sm.summary())
This produces the following output:
coef: const 6.98 X 2.97 p-values: const 0.000 X 0.000 R-squared: 0.96
For each one-unit increase in x, the outcome y increases by approximately 2.97, and this relationship is statistically significant. This is parameter estimation focused on inference.
Approach 2: Machine Learning Model with scikit-learn (Prediction)
# Split data X_train, X_test, y_train, y_test = train_test_split( df[["X"]], df["Y"], test_size=0.3, random_state=42, ) # Fit model model_ml = LinearRegression() model_ml.fit(X_train, y_train) # Predict and evaluate y_pred = model_ml.predict(X_test) rmse = mean_squared_error( y_test, y_pred, squared=False, ) print(f"Intercept: {model_ml.intercept_:.2f}") print(f"Coefficient: {model_ml.coef_[0]:.2f}") print(f"RMSE on test set: {rmse:.2f}")
This outputs the learned function and predictive accuracy, e.g.:
Intercept: 6.85 Coefficient: 3.02 RMSE on test set: 1.11
Here, the focus is on minimizing prediction error; we don’t get p-values or confidence intervals. Instead, we assess how well the model generalizes using metrics like RMSE.
While both models learned a similar linear relationship, the statsmodels output is centered on inference, giving statistical confidence and hypothesis testing. The scikit-learn model is optimized for predictive performance, emphasizing how well the model performs on unseen data.
Both methods fit the same general form:
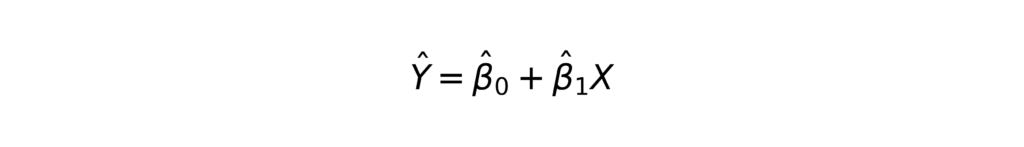
But one is built to explain β1, while the other is built to predict Y.
Interpretability and Transparency
One of the most frequently cited advantages of statistical models is their transparency. In a generalized linear model, each coefficient j has a clear meaning: it represents the expected change in the outcome variable per unit change in the predictor, holding all other variables constant. This makes statistical models especially valuable in domains where interpretability is crucial, such as clinical trials, epidemiology, and economics.
Machine learning models, particularly ensemble methods and deep learning architectures, often lack this transparency. While techniques such as SHAP values and partial dependence plots offer post hoc interpretability, they do not provide the same type of direct, causal explanation that a statistical coefficient does. In many cases, these interpretations are approximations or heuristics rather than analytically derived quantities.
When to Use What
Choosing between a statistical model and a machine learning model is not merely a technical decision; it depends on the question being asked, the nature of the data, and the consequences of the results.
When the goal is to test a scientific hypothesis, estimate causal effects, or inform policy based on clear variable relationships, statistical modeling is usually the appropriate choice. The emphasis here is on clarity, rigor, and defensibility. On the other hand, when the primary concern is making accurate predictions, handling large-scale or unstructured data, or building automated systems, machine learning methods offer unmatched flexibility and performance.
In practice, hybrid approaches are increasingly common. Machine learning algorithms can be used for variable selection or to detect nonlinearities, after which statistical models are applied for interpretation. Conversely, machine learning models can be made more interpretable through regularization, constraint-based learning, or model distillation.
Models Are Arguments About the World
Statistical models and machine learning models are not interchangeable. They are designed to answer different kinds of questions. One is built to uncover relationships and draw inferences based on a set of theoretical assumptions. The other is optimized for performance and flexibility when working with uncertain or noisy data. Both have value. Both can fail. And neither lets us off the hook when it comes to understanding what we’re doing and why.
In the end, every model makes a claim about the world. Knowing which claim you’re making, and what compromises you’re willing to accept, is what separates thoughtful analysis from blind automation.



